






 BTC/HKD+0.45%
BTC/HKD+0.45% ETH/HKD+0.73%
ETH/HKD+0.73% LTC/HKD+2.02%
LTC/HKD+2.02% DOT/HKD-0.01%
DOT/HKD-0.01% ADA/HKD+0.2%
ADA/HKD+0.2% SOL/HKD+1%
SOL/HKD+1% XRP/HKD-0.02%
XRP/HKD-0.02% DOGE/US+2.93%
DOGE/US+2.93%作者:SrinivasGumparthi博士,VenkataVaraPrasad博士
來源:SSRN
發布:2022.08.31
摘要
目的:股票價格預測一直作為一門研究課題,因為它在國家宏觀經濟中具有重要的作用。很難用一組特定的公式寫下股票的未來價值。當我們預測一只股票的未來價格時,許多因素都會出現。其中最重要的是歷史價格和成交量數據。
方法:隨著機器學習的興起,人們提出了多種預測股票價格的方法。目前,已開發了RNN、LSTM、CNN滑動窗口等各種模型,但都不夠精確。這項工作的興趣在于預測股票的價格,以及比較使用兩種算法,即KalmamFilters和XGBoost,并獲得結果。KalmamFilters本質上是遞歸的,并使用反饋機制進行誤差校正。這種修正能讓他們做出準確的預測,因為它們可以將市場波動考慮在內,而XGBoost對于非線性數據集來說是一種很有前途的技術,可以通過檢測數據中的模式和關系來收集知識。此外,XGBoost還能有效地捕獲特征的時間依賴性。
新穎性:最后,結合KalmamFilters和XGBoost開發了一個Hybrid模型,給出了未來投資和股票預測所需的完美預測。與KalmamFilters和Hybrid模型相比,XGBoost的平均準確率更高。
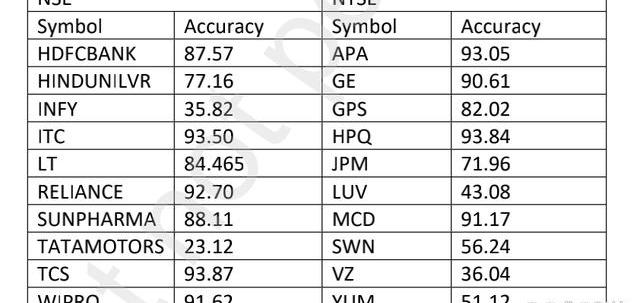
研究結果:混合模型似乎能準確地預測樣本的未來趨勢,但并不是對所有樣本都能做到這一點。XGBoost模型對NSE數據集的平均準確率為88.66%,對NYSE數據集的平均準確率為90.11%。KalmamFilter模型對NSE數據集的平均準確率為89.09,對NYSE數據集的平均準確率為64.96。該Hybrid模型對NSE數據集的平均準確率為76.79%,對NYSE數據集的平均準確率為70.91%。然而,對于個股,Hybrid模型表現優于XGBoost和KalmamFilter。
關鍵字:XGBoost,KalmanFilter,Hybrid模型,NSE,NYSE,市場情緒
1.介紹
如今,股票市場已成為大家的一個重要投資領域,很多普通人也對股票投資很感興趣。受環境、和其他社會因素的影響,股票市場價格波動很大。因此,有必要對股票價格預測進行廣泛分析。早期的統計模型和機器學習模型用于股票價格的預測。但考慮到歷史數據,數據量越來越大,這些模型在股票價格預測方面的準確性逐漸下降。因此,在當前的工作中,作者提出了一種結合統計和機器學習模型的混合模型。利用Kalmanfilter和XGBoost的優點來提高預測準確度。
很多研究人員使用各種統計和機器學習模型來解決這個問題。很少有人研究這些模型的組合,也很少有人給出印度股市帶來的顯著結果。Chatziset等人的研究旨在利用機器學習技術預測股市危機事件。該方法是基于尋找股票市場崩盤事件在不同時間框架的概率。考察了股票、債券和貨幣市場之間的交叉傳染效應。使用模型預測日收益,利用對數收益的平方計算日波動率。XGBoost在1天和20天內都有最佳的經驗表現。
基于云的加密礦工正利用GitHub Actions和Azure虛擬機非法挖礦:7月16日消息,GitHub Actions和Azure虛擬機(VM)正被用于基于云的加密貨幣挖礦,表明惡意行為者持續試圖以非法目的攻擊云資源。
Trend Micro研究人員Magno Logan在上周的一份報告中表示:“攻擊者可以通過惡意下載和安裝自己的加密貨幣礦機來濫用GitHub提供的runners或服務器,以運行組織的pipeline和自動化,從而輕松獲利。”
Trend Micro表示,他們發現了不少于1000個資料庫和550多個代碼樣本使用GitHub提供的runners并利用該平臺來進行加密貨幣挖礦。該代碼托管服務已經被通知了這個問題。(OODALoop)[2022/7/16 2:17:01]
Sen等人使用具有反向傳播算法的ANN作為訓練階段,并使用多層前饋網絡作為預測股票價格的網絡模型。研究了一種基于ANN的股票交易決策支持系統。本文還討論了基于決策過程的神經網絡的研究進展。該模型隨輸入值和時期的不同組合而變化。它輸出性能曲線、誤差曲線和輸出圖形。驗證效果良好,回歸值為0.996。
Dey等人將各種深度學習算法與XGBoost進行比較,以預測Yahoo數據集的股票市場回報。預測周期分別為28天、60天和90天。已經計算了每一項的準確性、預測性、召回率和特異性。繪制每個模型的假陽性率。
Karyaet等人在論文中,采用集合卡爾曼濾波平方根法和集合卡爾曼濾波法對股票價格進行預測。模擬結果表明,EnKF方法的估計結果比EnKF-SR方法更精確,即EnKF方法的估計誤差約為0.2%,而EnKF-SR方法的估計誤差為2.6%,。
Mortezaet等人的項目,試圖在NSE上使用機器學習技術來預測股票的未來價格,他們使用線性回歸和SVM回歸。線性回歸將使用股票前一天的收盤價來預測股票第二天的開盤價。SVM回歸將用于預測第二天股票的收盤價和開盤價之間的差值。外匯匯率、NSE指數、移動平均線、相對強弱指數等外部因素,被用來獲得最大的準確性。
DevShah等人在論文中,討論了股票市場分析的技術和基本方法。在技術分析中詳細討論了統計、機器學習、模式識別、情感分析和混合技術,還考慮了算法交易。作者總結說,包含混合和統計的機器學習技術,將產生更好的結果。人工神經網絡是人工智能的一部分,是一種識別數據中隱藏的、未知的、適合股票市場預測模式的常用方法。所選股票的歷史數據用于建立和訓練模型。
Song等人在論文中,將RNN-LSTM模型與SVM和XGBoost進行了比較。數據集是通過應用Python庫從GoogleFinance的API中獲得的。選擇了20家在NASDAQ和NYSE交易的公司。考慮了RSI、ADX和拋物線SAR等指標。通過繪制測試集誤差圖來比較結果。
Wanjawaet等人的研究,提出使用具有多層感知器的前饋人工神經網絡,通過反向傳播來預測股票價格。該模型分4個階段進行迭代。數據集來自內羅畢證券交易所和NYSE。通過改變隱藏層和感知的數量進行調優。每個調優實驗都基于前一個實驗模型進行的。最終模型的配置比為5:21:21:1,使用80%的可用數據進行訓練。采用均方根誤差作為參數,將獲得的結果與原始結果進行比較。結果表明,該模型對股票價格的預測具有較好的效果。
新加坡中央銀行探索利用區塊鏈技術實現多個CBDC之間的跨境支付:8月28日消息,新加坡中央銀行,新加坡金融管理局(MAS),啟動了一個新的基于區塊鏈技術的項目,以簡化使用中央銀行數字貨幣(CBDC)的跨境支付流程。MAS正在與國際清算銀行(BIS)合作開展一個名為Dunbar的項目,由一個對CBDC開發感興趣的其他中央銀行組成的財團組成。Dunbar項目將根據先前在國際清算銀行領導下的涉及CBDC的類似項目的實驗上進行開發。Quorum是由摩根大通的開發人員創建的以太坊分叉,并于2020年8月被以太坊的開發商ConsenSys收購。這項實驗還得到了摩根大通區塊鏈和支付基礎設施部門Onyx的支持。新加坡國際清算銀行創新中心主任Andrew McCormack指出,Dunbar還旨在展示共享CBDC結算平臺的力量和效用。
此前報道,MAS成功地模擬了其與法國銀行之間的跨境轉移交易,實驗結果是通過Quorum將新加坡元(新元)CBDC兌換成歐元(EUR)。(鳳凰新聞)[2021/8/28 22:43:21]
徐等人進行了比較文獻調查,證明ANN比SVM預測更準確。使用反向傳播訓練若干個前饋ANN。該評估是在NASDAQ證券交易所進行的,采用了6個月的數據集。模型的輸入是短期歷史股票價格和每周的天數。通過對每個隱藏層中神經元數目和設置不同的值,來優化神經網絡的結構。
鄭紅英等人提出了一種新的深度學習模型-隨機長短期記憶,旨在防止過擬合。該模型由Modaugnet-C框架和另一個用于預測的LSTM模塊組成,Modaugnet-C框架通過一個LSTM模塊和另一個LSTM模塊來增強單個LSTM模塊的潛力,其中一個LSTM模塊可以使用額外的增強數據來降低過擬合的風險,這些數據與用于預測的股票數據有很強的相關性。這在SSEC和S&P500數據集上進行了測試,該模型在準確性上優于其他模型。
WidodoBudiharto提出了一個模型,該模型結合了LSTM和基于R語言的統計計算,用于預測Covid-19大流行期間印度尼西亞交易所的股票。該模型在預測不到一年的短期數據時表現良好,準確率達94.5%,超過了長期數據的預測。
SalvatoreM.Cartaet等人使用機器學習方法,借助決策樹的二元分類技術來衡量未來股票價格波動的幅度。這些詞匯是從全球發表的文章、行業相關新聞等中識別和生成的。這些數據將與提取的特征一起輸入到預測模型。這在S&P500指數公司進行了測試,但準確率只有50-60%。
Milad等人比較了人工神經網絡和啟發式算法與傳統的時間序列模型來預測股票價格。這些模型用于各種國際指數,如Nasdaq指數、S&P500指數和DJI指數。與時間序列模型比較,ANN模型的誤差最小,預測效果更好。
Zelingheret等人測試使用各種機器學習模型來預測玉米價格的波動。他們考慮了線性模型,分類和回歸樹,隨機森林,梯度聚類。這些方法基于均方根誤差、漏一交叉驗證等,證明對玉米價格預測有效。
Chetan等人使用多種機器學習算法進行了比較研究,并結合情緒分析來預測Covid-19大流行期間的股票價格,因為這個時期社交媒體存在大量情緒。在所考慮的模型中,邏輯回歸模型表現最好,而KNN模型的準確性最低。
河北省嚴厲打擊利用虛擬貨幣、“一帶一路”等概念非法集資行為:近日,河北省打擊和處置非法集資工作領導小組印發《2018年防范非法集資宣傳月活動工作方案》,決定于5-6月組織開展全省范圍的防范打擊非法集資集中宣傳月活動,提高社會公眾的法律金融知識水平和風險防范意識,從源頭上遏制非法集資高發蔓延勢頭。方案提出,通過以案說法等方式介紹非法集資的特征、表現形式和常見手段,使群眾有效識別非法集資。針對民間投融資類中介機構、網絡借貸平臺、私募基金、股權眾籌、養老等案件高發重點領域,加強舉報獎勵政策宣傳,鼓勵群眾舉報非法集資線索。[2018/5/25]
2.設計和方法
預測模型的架構圖。首先清理從NSE獲得的數據集,以檢查空值,并獲取從YahooFinance收集的市場情緒數據。然后對其進行預處理,以獲得各種其他特征,例如調整后的閉合因子、閉合偏移、開啟偏移、開啟差、閉合差、高差和低差等。輸入正在清理的庫存數據。然后將該數據發送到三個模型中的每一個。在第一個模型——KalmanFilter,數據在每次迭代時都要經過預測和更新步驟。在預測步驟中,根據在前一時間步驟K-1更新的特征計算下一時間步驟K的收盤價。在更新步驟中,與前一時間步驟的預測相對應的特征被更新。在XGBoost中,數據集經歷兩個階段——擬合和預測。在擬合階段,該模型遞歸地構建各種決策樹,將范圍縮小到損失函數值最小的決策樹。在預測階段,使用此決策樹進行下一步的預測。對于Hybrid模型,我們首先運行XGBoost算法來執行特征選擇。這些特征輸入到KalmanFilter,預測股票的收盤價。然后,我們執行輸出分析以比較模型的結果。
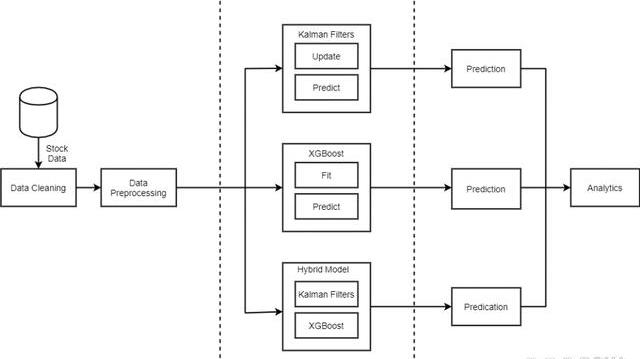
圖1體系結構圖
2.1KalmanFilter
在統計學中,KalmanFiltering是一種算法,使用一系列測量數據,包含隨時間推移觀察到的統計噪聲和不準確性。該算法對未知變量的估計往往比僅基于單一特征的估計更準確。它估計每個時間段變量的聯合概率分布。KalmanFilter是以RudolfE.Kalman名字命名的,他是該理論的主要開發者之一。
Xk=Fk*Xk+BkUk+Wk
Fk是應用于先前狀態Xk-1的狀態轉換模型,
Bk是應用于控制向量Uk的控制輸入模型,
Wk是假定從零均值多元正態分布中提取的過程噪聲。
2.2XGBoost
XGBoost是一種以開源方式實現的高效且流行的梯度增強樹算法。梯度提升是一種監督學習算法。XGBoost試圖通過組合一組更簡單、更弱的模型的估計值來準確預測目標變量。
XGBoost是一種集成學習方法。集成學習提供了一種系統的解決方案,結合了多個學習者的預測能力。結果是一個單一的模型,它來自多個模型的聚合輸出。形成集成的基本學習者,可以來自相同的學習算法或不同的學習算法。廣泛使用的集成學習者是Bagging和Boosting。XGBoost最主要的用途是決策樹,其次是統計模型。
金色財經現場報道 百慕大總理David Burt:百慕大是唯一一個真正實現利用加密技術的國家:金色財經現場報道,今日在Coindesk 2018共識會議正式在紐約開幕。百慕大總理David Burt發表了演講,許多國家都在談論加密技術,但百慕大是唯一一個真正實現利用加密技術的國家。百慕大6個月以來引入許多區塊鏈項目,并制定了相關的法律。百慕大歡迎并支持創新。此前,在4月28日,百慕大總理接見幣安CEO趙長鵬,并探討數字資產領域問題。雙方簽署了諒解備忘錄,幣安宣布將投入至少1500萬美元用于區塊鏈相關的教育和創業活動,并幫助百慕大政府制定加密貨幣和區塊鏈的監管框架,在該國建立新的辦事處。以促進百慕大人民未來的發展,就業和機會。[2018/5/15]
當使用梯度提升進行回歸時,每個回歸樹都將一個數據點映射到它的一個連續葉子上,且弱學習者是回歸樹。XGBoost最小化了一個正則化目標函數,該目標函數結合了凸損失函數和模型復雜性的懲罰項。訓練迭代地進行,添加新樹來預測先前樹的殘差,然后將這些樹與先前樹組合起來,以進行最終的預測。被稱之為梯度提升,是因為它使用梯度下降算法來最小化添加新模型時的損失。
3.數據集及其實現
3.1數據集
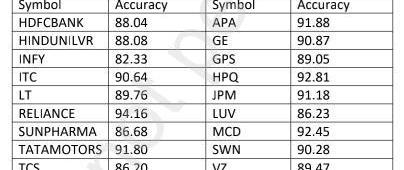
該數據集包含來自紐約證券交易所和國家證券交易所的10個腳本的股票價值。股票的名稱及其符號如下表1所示。
表1:顯示了所考慮的數據集
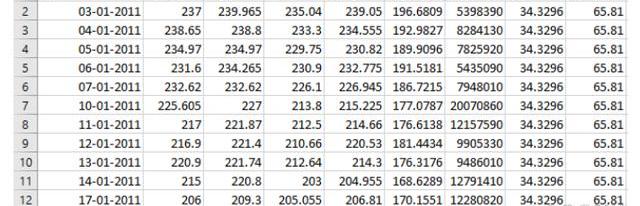
HDFCBANK數據的樣本如表2所示。它由開盤價、收盤價、最高價、最低價、交易量、調整后收盤價、每股收益、市盈率等列組成。我們既考慮了股票的基本面,也考慮了市場情緒,這有助于我們更好地預測。
表2:來自NSE的HDFC銀行數據集
我們使用皮爾遜相關矩陣發現了每一對特征之間的數據相關性。如圖2所示。數據關聯有助于理解數據集中多個變量和屬性之間的關系。使用相關性,我們可以獲得一些見解,例如一個或多個屬性依賴于另一個屬性,或另一個屬性的原因,以及一個或多個屬性與其他屬性相關聯。

圖2數據集中特征的相關性
對數據集進行預處理以獲得其他特征,例如調整因子、調整閉合位移、開放位移、高差、低差、開放差和關閉差等特征。預處理后的數據集如表3所示。
表3:預處理的HDFC數據集
調整后的收盤價和開盤價有助于將前一天調整后的收盤價和開盤價與第二天調整后的收盤價和開盤價相關聯。開盤價、最高價、最低價和收盤價分別乘以調整因子,使其與調整后的收盤價相對應。
歐洲刑警組織搗毀利用加密貨幣交易所洗錢的販集團:據coindesk消息,歐洲刑警組織周一宣布,已經搗毀了一個通過芬蘭加密交易所,使用加密貨幣和信用卡,從西班牙到哥倫比亞洗錢超過800萬歐元的販集團。被指控的犯罪分子首先使用信用卡在哥倫比亞收回資金,由于擔心發現,他們隨后將資金轉換為加密貨幣,然后通過芬蘭的加密貨幣交易所轉換為哥倫比亞比索。根據一項聲明,此次調查由歐洲刑警組織協調,并由西班牙的Guardia Civil,芬蘭當局和美國國土安全部的調查機構一佟執行,最終11人被捕。大約有137人被調查,嫌疑人共使用了174個銀行帳戶。[2018/4/11]
PankajKumar博士的研究結果表明,每股收益是所選公司股票市場價格的可靠預測指標,市盈率對股票市場價格的預測有顯著影響。因此,從整體上看,每股收益是A股市場價格表現的主要反映指標。
3.2KalmanFilter
3.2.1初始化
卡爾曼濾波器類被定義為數據成員F、H、Q、R和P初始化為單位矩陣和X-平均或預測狀態估計。
3.2.2預測
該步驟必須預測系統的均值X和協方差P。當給定卡爾曼對象作為輸入時,函數predict執行預測。
3.2.3更新
該步驟計算給定待更新的特征Z及其標準偏差R系統的均值X和協方差p。函數更新執行X,y的更新,S,K,P。矩陣乘法利用向量的點積。
對于每個時間步長K,執行預測和更新步驟以獲得預測值。該預測數組由必須進行預測的日期相對應的收盤價組成。這些值取決于參數,如打開、高、低、調整關閉、調整關閉位移、開放位移、EPS、PE比率等。在這一步之后,我們必須通過對照地面實況來計算預測中的誤差。對于此計算,我們使用絕對百分比誤差的平均值,其計算公式為:error=*100/]*100)。預測圖是在考慮的整個時期內繪制的。為此,我們使用Python中可用的matplotlib包。
3.3XGBoost
下面將詳細討論所涉及的算法和XGBOOST算法的實現細節。該實現是在Anaconda框架下使用Python完成的。
3.3.1Bagging
盡管決策樹是最容易解釋的模型之一,但決策樹表現出高度可變的行為。考慮將被隨機分成兩部分的單個訓練數據集。每個部分將訓練一個決策樹以獲得兩個模型。當這兩個模型都符合時,它們將產生不同的結果。由于這種行為,決策樹被認為與高方差有關聯。Bagging或Boosting聚合有助于減少任何學習者的差異。并行創建的幾個決策樹構成了Bagging技術的基礎學習者。用替換后的樣本數據對這些學習者進行訓練。最終的預測輸出是所有學習者的平均輸出。
3.3.2Boosting
在Boosting中,所有的樹都是按順序構建的,這樣每個后續的樹都會減少前一棵樹的錯誤。每棵樹從它的前項中學習并更新錯誤。因此,所有后續的樹將從錯誤的更新版本中學習。偏差很高的基礎學習者是弱學習者,預測能力只比偶然猜測強一點點。每一個弱學習者都為預測提供了重要信息,從而通過組合這些弱學習者來產生一個強學習者。最后一個和最后的強學習者具有較低的偏差和方差。
與隨機森林等Bagging技術形成鮮明對比的是,XGBoost中的Boosting模型利用了分裂次數較少的樹。這樣的小樹是高度可解釋的,因為樹的深度非常小。迭代次數或樹的數量、梯度提升的學習率和樹的深度等參數,可以通過k-fold交叉驗證等驗證技術進行優化選擇。過擬合是由于樹太多造成的。因此,有必要謹慎選擇助推的停止標準。
3.4HybridModel
HybridModel是統計模型,Kalmanfilter和機器學習模型XGBoost的組合。Hybrid模型有助于正確預測股票價值,提高各種數據集的準確性和一致性。當利益變量不能直接測量時,Kalmanfilters可以最優地估計感興趣的變量,間接測量是可用的。對于這種間接測量,可以使用14個參數。通過特征提取,XGBoost算法在14個參數中根據權值取前5個參數。前5個參數因股票而異。將這5個參數輸入Kalmanfilter,對未來股票價值進行預測,并提取輸出。
通過在測試集中輸入no,對以下每個模型進行測試,測試集包含400天的庫存數據,預測必須在幾天后進行。所有的模型都用兩個不同的數據集進行了測試——一個由價格變動組成,另一個由價格變動和市場情緒組成。價格變動包括開盤價、最高價、最低價、收盤價、成交量、股息率、成交量等數據。市場情緒是指投資者對某一特定證券的整體心理。這是普通大眾的感覺,通過證券交易的價格變動表現出來。極高的市盈率表示給定股票的價格很高,隨時可能下跌。在這種情況下,可以說股票超買了。低市盈率表明對公司的業績和未來缺乏信心。每股收益是指公司持有的每股股票的收益。它是衡量公司盈利能力的指標。通常優選較高的EPS。
3.4.1Kalmanfilter
下圖描述了該模型在考慮市場情緒前后的HDFC銀行數據集預測。我們可以看到,該模型在后一種情況下表現得更好。如圖3所示,僅考慮價格變動,我們的準確率僅為88%。但如圖4所示,考慮市場情緒后,我們的準確率為91.75%。準確率大大提高。
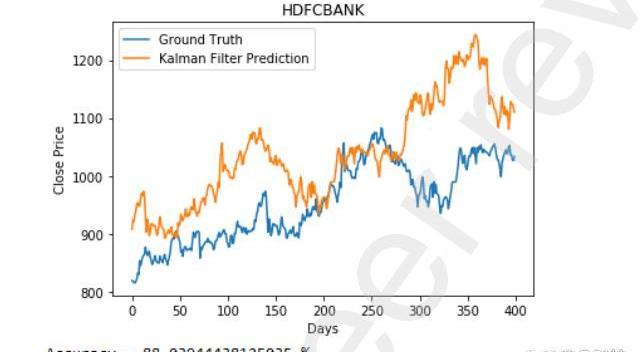
圖3不考慮市場情緒的HDFC預測
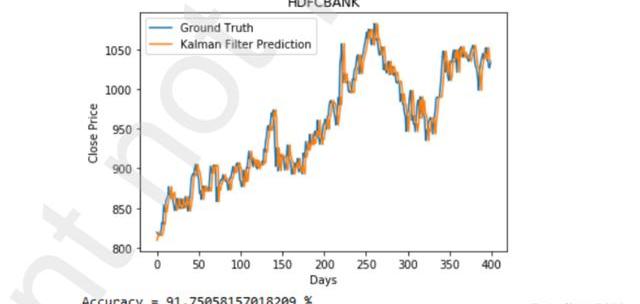
圖4考慮市場情緒的HDFC預測
該模型還針對18個可用數據集中的其余數據集進行了測試,這些數據集總結在下表4中。
表4不同數據集的Kalmanfilter模型準確性
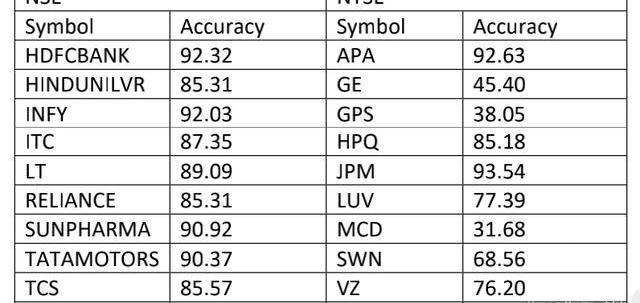
從上述結果中我們可以看出,該模型對NSE的各種數據集的表現是一致的,并且可以依賴該模型做出更好的預測,但對于NYSE,準確率并不一致且不高。
3.4.2XGBoost
XGBoost模型是為國家證券交易所的HDFC銀行數據集和紐約證券交易所的JPMorgan數據集開發的。這些模型是在有市場情緒和沒有市場情緒的情況下訓練的。不同于KalmanFilters在加入市場情緒后會產生準確率和誤差率的顯著變化,XGBoost中的準確率和誤差率保持不變。因此,在進一步的訓練中考慮了市場情緒。在為數據建立模型后,JPMorgan
和HDFC銀行的測試數據的準確率分別為91%和88%。

圖5考慮市場情緒的HDFC數據集的準確性

圖6考慮市場情緒的JPM數據集的準確性
圖5和圖6分別顯示了測試HDFCBank和JPMorganandChase數據集時獲得的準確性和誤差。
圖7訓練HDFC數據集時增強回歸樹的權重

圖8訓練JPM數據集時增強回歸樹的權重
圖7和圖8顯示了在訓練模型時獲得的增強回歸樹的權重,然后用于進一步預測訓練集。
該模型還針對18個可用數據集中的其余數據集進行了測試,這些數據集總結在下表5中。
表5XGBoost模型在不同數據集上的準確性
3.4.3Hybrid模型
兩個不同公司股票的模型結果,如下所示。
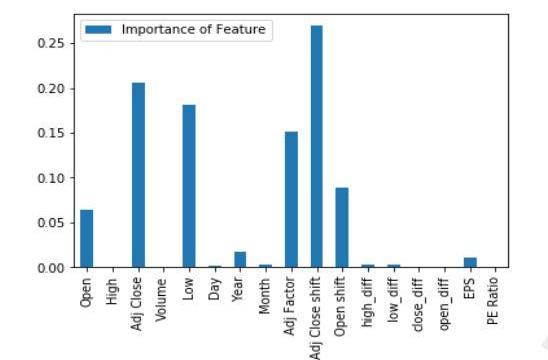
圖9XGBoost為HDFC數據集發現的功能重要性
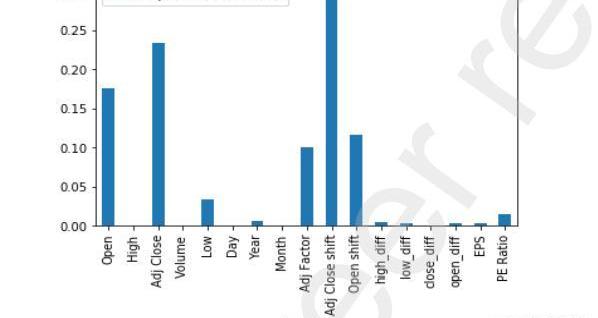
圖10XGBoost為JPM數據集找到的功能重要性
從上面通過實現XGBoost算法獲得的圖9和圖10中,我們可以找到預測時在增強回歸樹中起最重要作用的特征。我們只考慮上述步驟中的前5個特征,并將這些特征提供給KalmanFilter模型,以進行最終的股票價值預測。
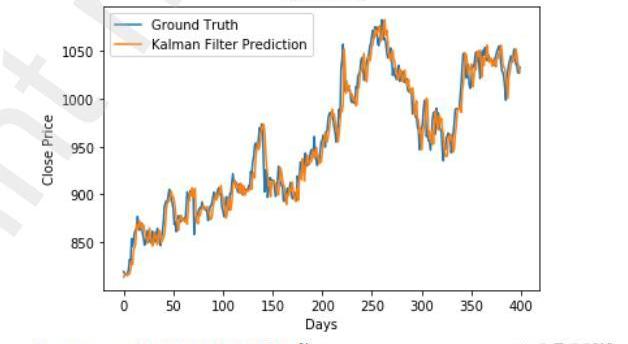
圖11Hybrid模型對HDFC數據集的預測
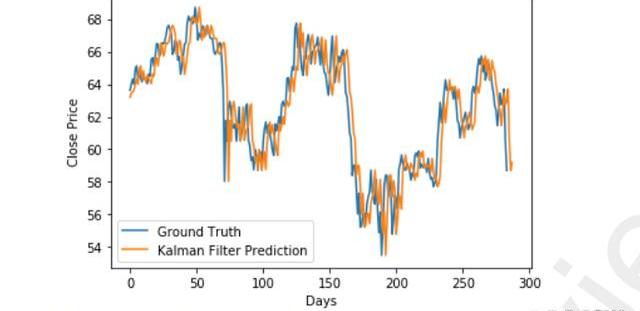
圖12Hybrid模型對JPM數據集的預測
該模型在不同的數據集上表現一致。圖11和圖12顯示,對于兩個數據集,該模型的準確度優于其他兩個單獨模型所獲得的準確度。
該模型還針對18個可用數據集中的其余數據集進行了測試,這些數據集總結在下表6中。
表6不同數據集的混合模型準確度
4.結論
股票市場預測分析是在20個樣本上進行的,其中10個屬于國家證券交易所,另外10個屬于紐約證券交易所。平均而言,10年期間的股票價值由每個樣本2300行組成。所考慮的時間區間為2006年-2016年和2010年-2020年。XGBoost模型與用于分析的20個樣本是一致。XGBoost模型對NSE數據集的平均準確率為88.66,對NYSE數據集的平均準確率為90.11。盡管KalmanFilter統計模型產生了令人印象深刻的結果,但模型的準確性并不一致。KalmanFilter模型對NSE數據集的平均準確率為89.09,對NYSE數據集的平均準確率為64.96。混合模型似乎可以很準確地預測腳本的未來趨勢,但它不能對所有樣本都這樣做。Hybrid模型對NSE數據集的平均準確率為76.79,對NYSE數據集的平均準確率為70.91。將每個季度的市場情緒添加到所有樣本中,似乎可以提高三個模型的準確性。當數據集由更高價值的股票數據組成時,混合模型似乎優于其他兩個模型。
5.未來
論文中描述的三個模型都給出了良好的準確度和一致的結果。但Hybrid模型在股票價值的未來預測方面是最好的,它預測了市場的高點和低點,并提高了效率。作為項目的未來工作,我們可以考慮一組樣本來進行樣本選擇。然后,我們可以在這些樣本上執行投資組合管理,其中模型返回所需的投資、可接受的風險和手頭的投資金額。
6.參考文獻:

金融學有哪些被ssci收錄?受金融學方向研究人員所托,在這里分享了60本ssci收錄的金融學期刊,這些期刊注重學術公平,設有專門的投稿系統,采用雙向或者單向盲審的方式,投稿過程規范,審稿客觀.
1900/1/1 0:00:00IT之家12月2日消息,SawyerMerrit發現,特斯拉ModelY和Model3從12月開始在美國市場開啟一輪降價,幅度可達3750美元,折合約2.64萬元人民幣.
1900/1/1 0:00:00當Web3.0來臨之際,區塊鏈技術引導的去中心化變革正在產生深遠影響。在這場變革中,數據不僅是促進社會經濟運轉的重要生產要素,也成為了具備價值流通和傳承的資產,它的存儲方式也正受到前所未有的關注.
1900/1/1 0:00:00展快速根據IBM的數據顯示,人類每天都在創建和存儲近2.5萬億字節的數據,企業和組織正試圖最大限度地利用他們已有的數據,并確定他們還需要捕獲和存儲哪些數據.
1900/1/1 0:00:00根據JohnBollinger的說法,比特幣和以太坊已經沉睡,而萊特幣已經蘇醒。他指的是BTC、ETH和LTC近期的市場價格表現.
1900/1/1 0:00:00我們不能從區塊鏈生態系統中奪走社區。有些代幣是為社區而設計的,它們可以被標記為社區代幣。社區驅動的代幣是通往社區的門戶。它們用于鼓勵參與并推動生態系統內項目的炒作.
1900/1/1 0:00:00


